Auswertung einer umfrage: So interpretierst du Daten überzeugend

Bevor es an die spannende statistische Auswertung geht, steht ein entscheidender, oft unterschätzter Schritt an: die Aufbereitung und Bereinigung der Rohdaten. Dieser Prozess ist das Fundament deiner gesamten Analyse. Ohne ihn sind selbst die cleversten statistischen Tests wertlos, denn fehlerhafte Daten führen unweigerlich zu falschen Schlussfolgerungen.
Vom Fragebogen zum sauberen Datensatz
Stell dir deine Rohdaten wie ein frisch geerntetes Feld vor. Bevor du etwas daraus kochen kannst, musst du erst mal Unkraut jäten und die Spreu vom Weizen trennen. Genau das ist die Datenbereinigung. Sie stellt sicher, dass du mit einem vertrauenswürdigen Datensatz arbeitest, auf den du dich verlassen kannst.

Diese systematische Prüfung ist übrigens nicht nur in der Wissenschaft entscheidend. Auch in der Wirtschaft ist es wichtig zu verstehen, was sind Audits und warum sie wichtig, denn auch hier bilden saubere Daten die Basis für jede fundierte Entscheidung.
Typische Datenfehler aufspüren
Die erste Runde der Datenprüfung fühlt sich oft wie Detektivarbeit an. Du gehst auf die Jagd nach allem, was seltsam oder unlogisch erscheint und deine Ergebnisse verzerren könnte.
Hier sind die üblichen Verdächtigen:
- Abbrecher und unvollständige Antworten: Jemand hat nur die ersten drei Fragen beantwortet und dann aufgegeben? Diese Antworten sind meist nicht brauchbar und sollten raus. Sonst verzerren sie das Gesamtbild.
- Offensichtliche Falscheingaben: Ein Alter von „999“ oder eine Studiendauer von „100 Semestern“ sind klare Tippfehler oder Scherzantworten. Solche Werte musst du als fehlend definieren, damit sie in Berechnungen nicht für Chaos sorgen.
- Durchklicker und Antwortmuster: Ein Teilnehmer, der bei 50 Fragen in einer Reihe immer die mittlere Antwortoption wählt? Das ist ein klassischer Fall von „Straight-Lining“. Solche Datensätze sind wertlos und sollten konsequent entfernt werden, da sie auf mangelnde Aufmerksamkeit hindeuten.
Diese erste Säuberungsaktion ist unverzichtbar. Sie schützt dich vor groben Fehlinterpretationen und sorgt dafür, dass deine Analyse auf echten, qualitativ hochwertigen Informationen basiert.
Der richtige Umgang mit fehlenden Werten
Fast jeder Datensatz hat Lücken. Das ist völlig normal. Die Frage ist nur, wie man damit umgeht. Deine Entscheidung hier hat direkte Folgen für die Aussagekraft deiner Ergebnisse.
Im Grunde gibt es drei gängige Strategien:
- Listwise Deletion (Fallweiser Ausschluss): Das ist die radikalste Methode. Jeder Teilnehmer, dem auch nur ein einziger Wert fehlt, fliegt komplett aus der Analyse. Das ist einfach umzusetzen, kann aber deine Stichprobe empfindlich verkleinern.
- Pairwise Deletion (Paarweiser Ausschluss): Hier ist man flexibler. Ein Teilnehmer wird nur für die eine Berechnung ausgeschlossen, bei der ihm der spezifische Wert fehlt. So rettest du mehr Daten, musst aber damit leben, dass deine Analysen auf leicht unterschiedlichen Stichprobengrößen basieren.
- Imputation (Werte ersetzen): Diese Methode füllt die Lücken auf, indem fehlende Werte durch statistische Schätzungen ersetzt werden, zum Beispiel durch den Mittelwert der jeweiligen Spalte. Das hält die Stichprobengröße konstant, birgt aber die Gefahr, die natürliche Streuung der Daten künstlich zu verkleinern.
Mein Tipp aus der Praxis: Für Haus- oder Abschlussarbeiten ist der fallweise Ausschluss (Listwise Deletion) meist der sicherste und pragmatischste Weg. Das gilt aber nur, solange du nicht mehr als 5 % deiner Fälle verlierst. Ganz wichtig: Dokumentiere im Methodikteil genau, wie du vorgegangen bist und warum. Transparenz ist hier alles!
Um dir den Einstieg zu erleichtern, habe ich hier die wichtigsten Schritte zusammengefasst.
Checkliste für die Datenvorbereitung
Die wichtigsten Schritte, um deine Rohdaten in einen analysefertigen Datensatz zu verwandeln.
| Aufgabe | Beschreibung | Warum es entscheidend ist |
|---|---|---|
| Daten importieren & prüfen | Lade deinen Datensatz in die Statistiksoftware und prüfe, ob alle Variablen und Werte korrekt eingelesen wurden. | Fehler beim Import können zu völlig falschen Berechnungen führen, die du später kaum nachvollziehen kannst. |
| Unrealistische Werte finden | Suche nach Werten, die unmöglich sind (z. B. Alter > 120) oder außerhalb des gültigen Bereichs liegen (z. B. eine 6 auf einer 5er-Skala). | Diese Ausreißer können Mittelwerte und andere statistische Kennzahlen massiv verzerren. |
| Antwortmuster erkennen | Überprüfe auf „Straight-Lining“ (immer die gleiche Antwort) oder auffällige Muster, die auf mangelnde Sorgfalt hindeuten. | Solche Datensätze repräsentieren keine echten Meinungen und verschlechtern die Datenqualität erheblich. |
| Umgang mit Fehlwerten festlegen | Entscheide dich für eine Methode (z. B. fallweiser Ausschluss) und wende sie konsistent an. | Eine inkonsistente Handhabung macht deine Ergebnisse schwer vergleichbar und weniger glaubwürdig. |
| Variablen umkodieren | Wandle textbasierte Antworten (z. B. „männlich“, „weiblich“) in numerische Codes (z. B. 1, 2) um. Skalen ggf. umpolen. | Die meisten statistischen Verfahren erfordern numerische Daten. Ohne diesen Schritt sind viele Analysen nicht möglich. |
| Dokumentation | Halte jeden einzelnen Schritt der Datenbereinigung schriftlich fest. Welche Fälle wurden warum ausgeschlossen? | Das schafft Transparenz und ermöglicht es anderen (und dir selbst), deine Analyse nachzuvollziehen und zu überprüfen. |
Diese sorgfältige Vorbereitung mag mühsam erscheinen, aber sie zahlt sich am Ende zigfach aus. Ein sauberer Datensatz ist die Grundvoraussetzung für jede erfolgreiche Auswertung einer Umfrage.
Ein guter Analyseplan beginnt übrigens schon viel früher. Wenn du noch am Anfang stehst, wirf einen Blick in unseren Leitfaden zur Entwicklung einer präzisen Forschungsfrage – sie ist der Kompass für deine gesamte Arbeit.
Erste Muster mit deskriptiver Statistik erkennen
So, der Datensatz ist bereinigt – Zeit, ihm erste Geheimnisse zu entlocken. An dieser Stelle kommt die deskriptive Statistik ins Spiel. Sie ist quasi dein erster Plausch mit den Daten, bei dem du ein Gefühl für die grundlegenden Tendenzen, Strukturen und Verteilungen bekommst. Bevor du dich also in komplexe Hypothesentests stürzt, verschaffst du dir erst mal einen soliden Überblick.

Dieser Schritt ist fundamental. Du siehst, wer überhaupt geantwortet hat, wie die Meinungen verteilt sind und ob sich schon erste interessante Muster abzeichnen. Ohne dieses Fundament sind alle späteren, tiefergehenden Analysen wackelig.
Von offenen Antworten zu greifbaren Kategorien
Eine klassische Herausforderung bei der Auswertung einer Umfrage sind offene Fragen. Antworten wie „Ich nutze die App hauptsächlich in der Bibliothek“ oder „Am besten lerne ich unterwegs im Zug“ sind Gold wert für das Verständnis, aber eine Qual für die Statistik. Hier musst du die Ärmel hochkrempeln und kodieren.
Beim Kodieren bündelst du inhaltlich ähnliche Antworten zu übergeordneten Kategorien. Aus den Beispielen oben könnten so Kategorien wie „Lernen an ruhigen Orten“ oder „Mobiles Lernen“ entstehen. Ja, das hat immer eine interpretative Komponente, ist aber unerlässlich, um aus qualitativem Text quantifizierbare Daten zu machen.
Wenn du tiefer in die thematische Bündelung von Textmaterial einsteigen möchtest, findest du in unserem Leitfaden zur qualitativen Inhaltsanalyse nach Mayring wertvolle Methoden.
Das Herz der Daten verstehen: Lagemaße
Nach dem Kodieren geht es an die zentralen Tendenzen. Diese Kennzahlen verraten dir, was der „typische“ Wert in deiner Stichprobe ist.
Die drei wichtigsten Maße sind:
- Der Mittelwert (oder Durchschnitt): Alle Werte addiert und durch die Anzahl geteilt. Super bei normalverteilten Daten (z. B. Körpergröße), aber extrem anfällig für Ausreißer. Ein einziger extrem hoher Wert kann den Durchschnitt komplett verzerren.
- Der Median: Der Wert, der genau in der Mitte liegt, wenn du alle Antworten der Größe nach sortierst. 50 % der Werte liegen darüber, 50 % darunter. Der Median ist robust gegenüber Ausreißern – perfekt für Skalenfragen, bei denen extreme Meinungen das Gesamtbild nicht dominieren sollen.
- Der Modus (oder Modalwert): Ganz simpel der häufigste Wert in deinen Daten. Bei der Frage nach dem Studienfach wäre der Modus das Fach, das am öftesten genannt wurde.
Stell dir vor, du fragst Studierende nach ihrer wöchentlichen Lernzeit. Die meisten lernen 10–15 Stunden. Ein Überflieger lernt jedoch 60 Stunden. Der Mittelwert würde durch diesen einen Ausreißer stark ansteigen, während der Median unberührt bliebe und ein realistischeres Bild der typischen Lernzeit zeichnen würde.
Die Streuung der Antworten analysieren
Den Durchschnitt zu kennen, ist nur die halbe Miete. Mindestens genauso wichtig ist die Frage, wie stark die Antworten um diesen Wert herum streuen. Sind sich alle ziemlich einig oder gehen die Meinungen meilenweit auseinander?
Hier kommen die Streuungsmaße ins Spiel:
- Die Spannweite: Der simple Abstand zwischen dem kleinsten und dem größten Wert. Gibt einen schnellen, aber sehr groben Überblick.
- Die Standardabweichung: Das ist das Arbeitspferd unter den Streuungsmaßen. Sie zeigt, wie weit die einzelnen Datenpunkte im Schnitt vom Mittelwert abweichen. Eine kleine Standardabweichung bedeutet hohe Einigkeit, eine große signalisiert stark voneinander abweichende Meinungen.
Ein Praxisbeispiel macht das sofort klar: Nehmen wir eine Umfrage zur Nutzung von Lern-Apps, in der du das Alter der Nutzer abfragst. Der Mittelwert liegt bei 23 Jahren. Eine kleine Standardabweichung von 1,5 würde bedeuten, dass die meisten Nutzer zwischen 21,5 und 24,5 Jahre alt sind. Eine große Standardabweichung von 5 hingegen würde zeigen, dass deine Nutzerbasis vom Erstsemester bis zum berufsbegleitenden Masterstudenten reicht.
Kombinierst du Lage- und Streuungsmaße, erhältst du ein erstes, erstaunlich detailliertes Profil deiner Stichprobe. Du weißt nicht nur, wer geantwortet hat, sondern auch, wie homogen oder heterogen deine Zielgruppe tickt. Diese Erkenntnisse sind entscheidend, um die Ergebnisse späterer, komplexerer Tests richtig einordnen zu können.
Zusammenhänge aufdecken mit Kreuztabellen und Chi-Quadrat-Tests
Nachdem die deskriptive Analyse dir einen ersten Überblick verschafft hat, wird es Zeit, tiefer zu graben. Denn die wirklich spannenden Erkenntnisse bei der Auswertung einer Umfrage schlummern oft unter der Oberfläche. Sie zeigen sich erst, wenn du anfängst, verschiedene Gruppen miteinander zu vergleichen.
Ist eine neue Funktion in deiner Lern-App bei Männern beliebter als bei Frauen? Hängt die Wahl des Studienfachs vielleicht mit der Vorliebe für digitale Lernformate zusammen? Genau für solche Fragen sind Kreuztabellen das perfekte Werkzeug.
Kreuztabellen, manchmal auch Kontingenztabellen genannt, sind erstaunlich schlicht und doch extrem wirkungsvoll. Sie stellen die Häufigkeiten von zwei kategorialen Variablen gegenüber und machen so auf einen Blick sichtbar, wie sich die Antworten verteilen. Statt nur zu wissen, wie viele Leute insgesamt zufrieden sind, siehst du plötzlich, wie sich die Zufriedenheit auf Altersgruppen oder Geschlechter aufteilt.
Kreuztabellen richtig erstellen und lesen
Eine Kreuztabelle ist schnell gebaut. Die Kategorien der einen Variable, zum Beispiel das Geschlecht (männlich, weiblich), packst du in die Zeilen. Die Kategorien der anderen, etwa die Nutzungshäufigkeit (täglich, wöchentlich, monatlich), kommen in die Spalten. In den Zellen der Tabelle zählst du dann einfach, wie viele Personen auf beide Merkmale zutreffen.
Der eigentliche Aha-Effekt kommt aber erst mit den Prozentwerten. Und genau hier lauern die typischen Fallstricke. Es ist absolut entscheidend, welche Basis du für deine Prozente wählst.
- Zeilenprozente sind dein Mittel der Wahl, wenn du die Gruppen in den Zeilen vergleichen willst. Die Frage lautet dann: „Wie viel Prozent der Männer nutzen die App täglich?“
- Spaltenprozente brauchst du, um die Gruppen in den Spalten zu vergleichen. Hier fragst du: „Wie viel Prozent der täglichen Nutzer sind männlich?“
Wer hier die falsche Berechnung wählt, kommt schnell zu völlig irreführenden Schlussfolgerungen. Mach dir also immer vorher klar, welche Geschichte du mit deinen Daten erzählen willst.
Ein typisches Beispiel aus der Praxis: Stell dir vor, du untersuchst den Zusammenhang zwischen dem Studienfach (Zeilen: BWL, Informatik) und der bevorzugten Lernmethode (Spalten: Videos, Texte). Du willst herausfinden, ob BWLer anders lernen als Informatiker. Also berechnest du die Zeilenprozente. Nur so kannst du am Ende eine Aussage treffen wie: „60 % der BWL-Studierenden bevorzugen Videos, während es bei den Informatikern nur 30 % sind.“
Ist der Unterschied echt? Die Rolle des Chi-Quadrat-Tests
Eine Kreuztabelle kann dir einen Zusammenhang zeigen – aber ist der auch statistisch signifikant? Oder sind die Unterschiede, die du siehst, vielleicht nur reiner Zufall? Diese wichtige Frage beantwortet der Chi-Quadrat-Test (χ²-Test). Er ist der logische nächste Schritt, sobald deine Kreuztabelle steht.
Im Grunde vergleicht der Test die Häufigkeiten, die du in deiner Umfrage beobachtet hast, mit den Häufigkeiten, die man erwarten würde, wenn es absolut keinen Zusammenhang zwischen den beiden Variablen gäbe. Je größer die Lücke zwischen Beobachtung und Erwartung, desto unwahrscheinlicher ist es, dass das Ergebnis ein Zufallstreffer war.
Das wichtigste Ergebnis, das dir der Test liefert, ist der p-Wert. Ist dieser Wert kleiner als ein vorher festgelegtes Signifikanzniveau (in den Sozialwissenschaften meist 0,05), dann gilt der Zusammenhang als statistisch signifikant. Das gibt dir die Sicherheit, dass der Unterschied nicht nur in deiner Stichprobe existiert, sondern mit hoher Wahrscheinlichkeit auch für die gesamte Bevölkerung gilt.
Ein Praxisbeispiel aus der Politikwissenschaft
Die Analyse des Wählerverhaltens ist ein Paradebeispiel für den Einsatz von Kreuztabellen. Hier werden demografische Merkmale wie Alter, Beruf oder Bildungsgrad mit der Wahlentscheidung gekreuzt, um typische Wählerprofile aufzudecken.
Ein Blick auf die Nachwahlbefragung zur Bundestagswahl 2025 zeigt faszinierende Muster. Bei den 18- bis 24-Jährigen schnitten Die Linke mit 25 % und die AfD mit 21 % stark ab. Ein ganz anderes Bild zeigte sich bei den Wählern über 70 Jahre: Hier dominierten die Union mit 50 % und die SPD mit 25 %. Die Daten belegen eindrücklich, wie stark das Alter die politische Präferenz prägt. Mehr dazu findest du in den detaillierten Ergebnissen zur Bundestagswahl 2025 auf statista.com. Ein Chi-Quadrat-Test würde hier ohne jeden Zweifel bestätigen, dass dieser Zusammenhang hochsignifikant ist.
Wenn du Kreuztabellen zur Visualisierung und den Chi-Quadrat-Test zur Absicherung nutzt, hebst du deine Analyse auf die nächste Stufe. Du gehst über reine Beschreibungen hinaus, deckst statistisch fundierte Zusammenhänge auf und gibst deiner Auswertung die wissenschaftliche Tiefe, die sie braucht.
Hypothesen gezielt auf den Prüfstand stellen: Statistische Tests in der Praxis
Nachdem du die ersten Muster und Zusammenhänge in deinen Daten entdeckt hast, kommt jetzt der vielleicht spannendste Teil bei der Auswertung einer Umfrage: das Testen deiner Hypothesen. Wir verlassen jetzt das Feld der reinen Beschreibung und begeben uns in die schließende Statistik. Hier geht es darum, von deiner Stichprobe auf die Allgemeinheit zu schließen und deine Forschungsfragen mit statistischer Substanz zu beantworten.
Dafür brauchst du das richtige Handwerkszeug. Statistische Verfahren wie der t-Test, die ANOVA oder die Regressionsanalyse helfen dir, über den reinen Zufall hinauszublicken und zu beweisen, dass deine gefundenen Effekte auch wirklich signifikant sind. Im Grunde beantworten sie immer die eine Frage: Ist der Unterschied, den ich hier sehe, echt oder könnte er auch zufällig entstanden sein?
Der t-Test: Das Duell zweier Gruppen
Der t-Test ist ein echter Klassiker und meist die erste Wahl, wenn du die Mittelwerte von genau zwei voneinander unabhängigen Gruppen vergleichen willst. Er ist unkompliziert, robust und gibt dir eine klare Antwort auf die Frage: Unterscheiden sich Gruppe A und Gruppe B in einem bestimmten Merkmal signifikant voneinander?
Stell dir vor, du hast in deiner Umfrage eine neue Lehrmethode untersucht. Deine Hypothese könnte lauten: „Studierende, die Methode A nutzen, erzielen bessere Klausurergebnisse als Studierende mit Methode B.“ Perfekt für einen t-Test. Er nimmt sich den Notenschnitt von Gruppe A und den von Gruppe B und vergleicht sie.
Das Ergebnis, das dich am meisten interessiert, ist der p-Wert. Er beziffert die Wahrscheinlichkeit, dass der Unterschied, den du da siehst, reiner Zufall ist.
Die magische Grenze: In den Sozialwissenschaften hat sich ein p-Wert von unter 0,05 als Schwelle für statistische Signifikanz eingebürgert. Das heißt: Die Wahrscheinlichkeit, dass dein Ergebnis durch Zufall zustande kam, liegt bei weniger als 5 %. Du kannst also mit recht hoher Sicherheit sagen: Der Unterschied ist echt.
Die ANOVA: Wenn mehr als zwei Gruppen im Spiel sind
Was aber, wenn du nicht nur zwei, sondern gleich drei oder mehr Gruppen hast? Nehmen wir an, du willst die Zufriedenheit von Studierenden aus drei Fachbereichen vergleichen – sagen wir BWL, Ingenieurwissenschaften und Sozialwissenschaften. Jetzt einfach dreimal einen t-Test zu rechnen (BWL vs. Ing, BWL vs. SoWi, Ing vs. SoWi), wäre methodisch ein grober Fehler, denn das würde deine Fehlerwahrscheinlichkeit künstlich aufblähen.
Genau hier kommt die Varianzanalyse (ANOVA) ins Spiel. Sie ist quasi die große Schwester des t-Tests und prüft, ob sich die Mittelwerte von drei oder mehr Gruppen irgendwo signifikant unterscheiden. Die ANOVA sagt dir aber erstmal nur, dass es einen Unterschied gibt – nicht, wo er liegt.
Um das herauszufinden, brauchst du im Anschluss sogenannte Post-hoc-Tests (ein beliebter ist der Tukey-HSD-Test). Diese Tests schaltest du nach einer signifikanten ANOVA und sie führen die Paarvergleiche für dich durch. So könntest du zum Beispiel feststellen, dass sich die BWL- und Ingenieurstudierenden signifikant in ihrer Zufriedenheit unterscheiden, aber zwischen BWL und Sozialwissenschaften kein Unterschied besteht.
Die Regressionsanalyse: Ein Blick in die Zukunft
Manchmal willst du aber nicht nur Unterschiede aufdecken, sondern gezielte Vorhersagen treffen. Wie stark beeinflusst die wöchentliche Lernzeit den Prüfungserfolg? Kann die Zufriedenheit mit dem Studium vorhersagen, ob jemand ein Masterstudium dranhängt? Für solche Fragen ist die Regressionsanalyse das Mittel der Wahl.
Die einfachste Form, die lineare Regression, versucht, eine abhängige Variable (z. B. die Klausurnote) durch eine oder mehrere unabhängige Variablen (z. B. Lernstunden, Motivation) zu erklären und vorherzusagen.
Ein paar wichtige Kennzahlen wirft dir das Modell dabei aus:
- Der R²-Wert (Bestimmtheitsmaß): Dieser Wert verrät dir, wie viel Prozent der Unterschiede (Varianz) in deiner abhängigen Variable durch deine gewählten Einflussfaktoren erklärt werden können. Ein R² von 0,40 würde bedeuten, dass sich 40 % der Unterschiede in den Klausurnoten durch die Lernzeit erklären lassen.
- Die Regressionskoeffizienten (Beta-Werte): Sie zeigen dir für jeden einzelnen Faktor, wie stark und in welche Richtung er wirkt. Ein positiver Wert bedeutet: je mehr Lernstunden, desto besser die Note.
Die Regression ist ein mächtiges Werkzeug, um komplexe Zusammenhänge zu verstehen. Du gehst damit weit über simple Vergleiche hinaus und kannst die eigentlichen Treiber hinter deinen Umfrageergebnissen identifizieren. Mit diesen inferenzstatistischen Verfahren gibst du deiner Auswertung einer Umfrage die wissenschaftliche Tiefe, die sie braucht, um deine Hypothesen fundiert zu bestätigen – oder eben auch zu verwerfen.
Daten visualisieren und die Geschichte dahinter erzählen
Reine Zahlen und Tabellen sind zwar präzise, aber sie sprechen selten für sich. Die wahre Kunst bei der Auswertung einer Umfrage liegt darin, diese Zahlen in eine packende Geschichte zu verwandeln. Eine gute Visualisierung macht deine Ergebnisse nicht nur verständlich, sondern auch greifbar und einprägsam. Sie ist das Sprachrohr deiner Daten.
Doch welches Diagramm erzählt deine Geschichte am besten? Das ist eine entscheidende Frage, denn die Wahl des richtigen Formats entscheidet darüber, ob deine Kernaussagen klar und unverfälscht beim Leser ankommen.
Die folgende Infografik ist eine super Orientierungshilfe. Sie hilft dir, je nach Forschungsfrage den passenden statistischen Test auszuwählen – und damit auch die Grundlage für die passende Visualisierung zu legen.
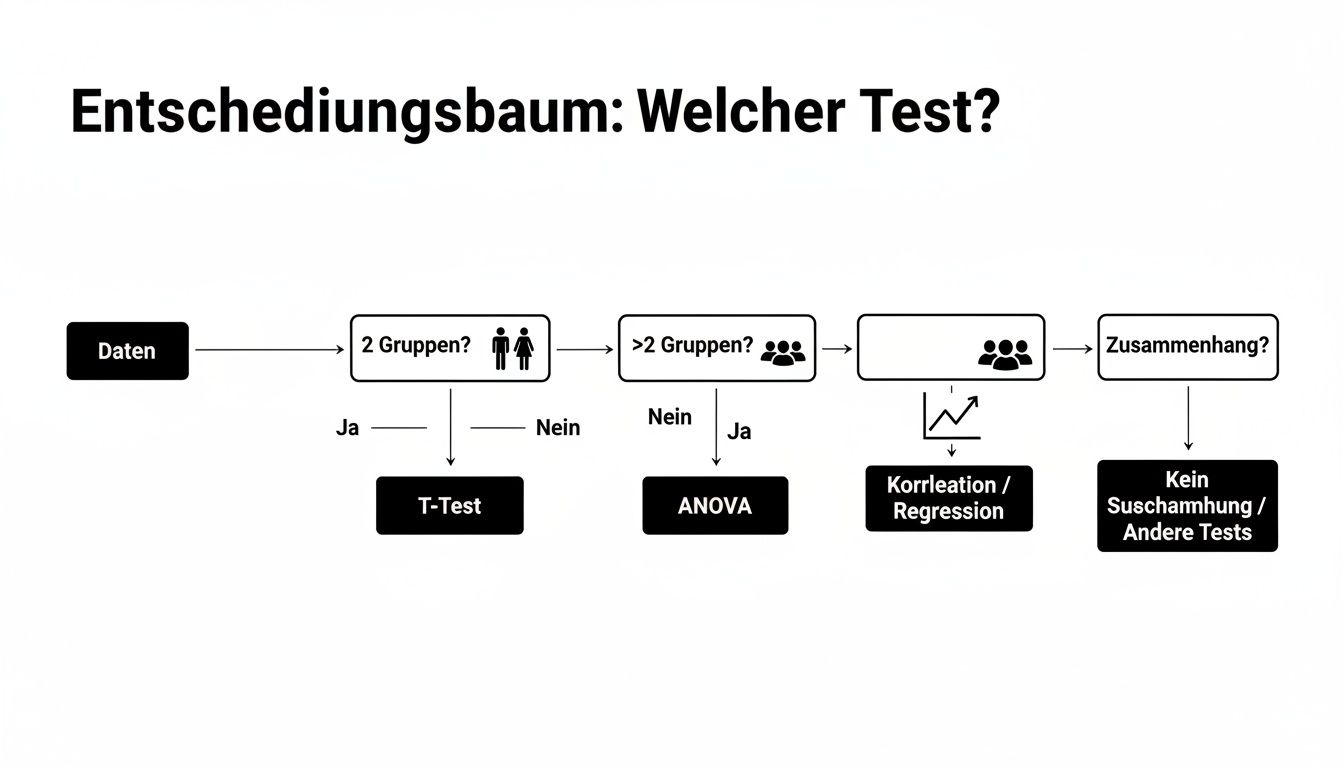
Wie du siehst, führen Fragen nach Gruppenunterschieden oder Zusammenhängen direkt zu spezifischen Testverfahren. Die Ergebnisse dieser Tests lassen sich dann wiederum ideal in bestimmten Diagrammtypen darstellen.
Das richtige Diagramm für deine Daten wählen
Klar, die Klassiker wie Balken- oder Kuchendiagramme kennt jeder. Die sind auch super, um einfache Häufigkeiten darzustellen – zum Beispiel, wie sich die Teilnehmenden auf verschiedene Studienfächer verteilen. Aber oft schlummern in deinen Daten viel komplexere Geschichten, die nach einer besseren Bühne verlangen.
Hier sind ein paar Optionen, die oft mehr Aussagekraft haben:
- Boxplots: Die sind unschlagbar, wenn du metrische Daten (wie Alter oder Zufriedenheitswerte auf einer Skala) zwischen mehreren Gruppen vergleichen willst. Ein Boxplot zeigt dir auf einen Blick den Median, die Streuung und eventuelle Ausreißer. Das ist so viel mehr als ein simples Balkendiagramm je könnte.
- Heatmaps: Perfekt, um Kreuztabellen zum Leben zu erwecken. Statt trockener Zahlen werden die Zellen farblich kodiert. So springen dir Muster und Zusammenhänge sofort ins Auge – etwa eine besonders hohe Zustimmung in einer bestimmten Altersgruppe.
- Streudiagramme (Scatterplots): Brauchst du immer dann, wenn du den Zusammenhang zwischen zwei metrischen Variablen untersuchst, zum Beispiel Lernaufwand und Klausurnote. Sie sind die visuelle Grundlage für Korrelations- und Regressionsanalysen und machen Trends sofort sichtbar.
Die Wahl des richtigen Diagramms ist also entscheidend, um deine Daten nicht nur zu zeigen, sondern sie auch verständlich zu machen. Die folgende Tabelle gibt dir eine schnelle Übersicht, wann welcher Diagrammtyp am besten passt.
Das richtige Diagramm für deine Daten
Eine Gegenüberstellung verschiedener Diagrammtypen und ihrer optimalen Anwendungsfälle bei der Umfrageauswertung.
| Diagrammtyp | Anwendungsfall | Beispiel |
|---|---|---|
| Balkendiagramm | Vergleich von Häufigkeiten oder Mittelwerten zwischen diskreten Gruppen. | „Wie viele Stunden lernen Studierende der BWL, Informatik und Psychologie?“ |
| Kreisdiagramm | Darstellung von prozentualen Anteilen eines Ganzen. Sparsam einsetzen! | „Prozentuale Verteilung der Teilnehmenden nach höchstem Bildungsabschluss.“ |
| Boxplot | Vergleich der Verteilung metrischer Daten (Median, Streuung, Ausreißer). | „Vergleich der Einkommensverteilung zwischen verschiedenen Berufsgruppen.“ |
| Histogramm | Visualisierung der Häufigkeitsverteilung einer einzelnen metrischen Variable. | „Wie ist die Altersverteilung aller Befragten?“ |
| Streudiagramm | Aufzeigen des Zusammenhangs zwischen zwei metrischen Variablen. | „Gibt es einen Zusammenhang zwischen der Bildschirmzeit und der Schlafqualität?“ |
| Heatmap | Darstellung von Mustern in großen Tabellen (z. B. Kreuztabellen). | „Welche Produktfeatures werden von welcher Kundengruppe am höchsten bewertet?“ |
Jedes Diagramm hat seine Stärken. Wähle immer das, welches deine zentrale Aussage am klarsten und ehrlichsten kommuniziert.
Mein Tipp aus der Praxis: Weniger ist oft mehr. Ein überladenes Diagramm mit 3D-Effekten, grellen Farben und ohne klare Beschriftung stiftet mehr Verwirrung als Klarheit. Konzentriere dich auf eine Kernaussage pro Grafik und sorge für eine minimalistische, saubere Gestaltung. Ganz wichtig: Achsen immer korrekt beschriften und die Skalierung bei Null beginnen lassen, um Verzerrungen zu vermeiden.
Von der Grafik zur Interpretation
Eine perfekte Grafik ist nur die halbe Miete. Jetzt musst du sie interpretieren und in den Kontext deiner Forschungsarbeit einbetten. Beschreibe nicht nur, was im Diagramm zu sehen ist, sondern erkläre, was es bedeutet.
Verknüpfe deine visuellen Ergebnisse direkt mit deiner Forschungsfrage und deinen Hypothesen. Bestätigt das Diagramm deine Annahmen? Widerspricht es ihnen vielleicht sogar? Genau das sind die Momente, in denen deine Analyse an Tiefe gewinnt.
Ein starkes Beispiel für die Aussagekraft von Umfragedaten ist die politische Meinungsforschung. Nehmen wir die Sonntagsfrage der Forschungsgruppe Wahlen vom 11. April 2025: Sie zeigte, wie präzise Umfragen das Wählerverhalten vorhersagen können. Damals lag die CDU/CSU bei 26 %, dicht gefolgt von der AfD mit 24 %. Vergleicht man das mit dem tatsächlichen Ergebnis der Bundestagswahl 2025, wo die Union 28,6 % holte und die AfD 20,8 % erreichte, waren die Prognosen erstaunlich nah dran. Die Abweichung bei den Spitzenreitern lag unter drei Prozentpunkten – ein Beleg für die Verlässlichkeit solcher Erhebungen. Wer tiefer einsteigen will, findet weitere Einblicke in die Umfragen zur Bundestagswahl auf statista.com.
Zum Schluss gehört es zum guten wissenschaftlichen Arbeiten, deine Ergebnisse mit der bestehenden Forschungsliteratur abzugleichen. Gibt es ähnliche Studien, die zu denselben oder anderen Schlussfolgerungen kommen? Diese Einordnung zeigt, dass du den wissenschaftlichen Diskurs verstanden hast und deine eigene Arbeit darin positionieren kannst.
Und nicht vergessen: Bei jeder Grafik in deiner Arbeit ist die korrekte Zitierweise Pflicht. Unser Leitfaden erklärt dir, wie die Quellenangabe von Bildern und Grafiken fehlerfrei gelingt. So wird aus einer einfachen Datendarstellung eine fundierte, überzeugende Argumentation.
Häufige Fragen zur Auswertung einer Umfrage
Wer schon einmal vor einem Datensatz saß, kennt das Gefühl: Man hat so viele Fragen. Gerade bei der Auswertung für eine wissenschaftliche Arbeit tauchen oft dieselben Hürden auf – von den grundlegenden methodischen Entscheidungen bis zum Umgang mit Ergebnissen, die so gar nicht ins Bild passen wollen.
Hier klären wir die typischen Stolpersteine, damit du mit mehr Sicherheit an deine Analyse gehen kannst.
Wie groß muss meine Stichprobe sein?
Das ist wohl die drängendste Frage von allen: „Wie viele Leute muss ich denn nun befragen?“ Die ehrliche, wenn auch unbefriedigende Antwort lautet: Es kommt darauf an. Eine Pauschalregel wie „100 Leute reichen immer“ ist wissenschaftlich leider Quatsch.
Die richtige Größe deiner Stichprobe hängt im Kern von drei Dingen ab:
- Größe der Grundgesamtheit: Willst du etwas über alle 20.000 Studierenden deiner Uni herausfinden? Dann brauchst du natürlich mehr Antworten, als wenn du nur deinen eigenen Studiengang mit 150 Kommilitonen untersuchst.
- Gewünschtes Konfidenzniveau: Wie sicher willst du sein, dass deine Ergebnisse nicht nur Zufall sind? In der Wissenschaft peilt man meist ein Niveau von 95 % an.
- Fehlermarge: Wie präzise sollen deine Ergebnisse sein? Eine akzeptierte Abweichung vom „wahren“ Wert in der Bevölkerung ist oft 5 %.
Für eine Hausarbeit wird aber meist ein pragmatischer Ansatz akzeptiert. Wichtig ist vor allem, dass du deine Stichprobe und deren mögliche Grenzen im Methodikteil deiner Arbeit sauber beschreibst und deine Entscheidungen begründest.
Was mache ich, wenn meine Ergebnisse nicht signifikant sind?
Erstmal: keine Panik! Der p-Wert liegt über 0,05 und deine Hypothese löst sich in Luft auf. Das fühlt sich oft wie ein persönliches Scheitern an, ist aber aus wissenschaftlicher Sicht ein völlig legitimes und sogar wichtiges Ergebnis. Ein nicht-signifikantes Resultat heißt nicht, dass deine Arbeit schlecht ist.
Ein Ergebnis, das keinen Zusammenhang zeigt, ist ebenfalls eine wertvolle Erkenntnis. Es trägt genauso zum Forschungsstand bei wie ein signifikantes Ergebnis, indem es aufzeigt, wo eben keine Effekte zu erwarten sind.
Deine Aufgabe ist es jetzt, genau das zu interpretieren. Woran könnte es gelegen haben, dass der erwartete Zusammenhang ausblieb? War die Stichprobe vielleicht zu klein oder zu speziell? War das Messinstrument nicht genau genug? Oder ist in der Realität vielleicht einfach kein Effekt da? Genau diese Diskussion macht oft den spannendsten Teil der Analyse aus.
Wie gehe ich mit unerwarteten Ergebnissen um?
Manchmal fördert die Auswertung Muster zutage, die allem widersprechen, was du erwartet hast oder was die bisherige Forschung sagt. Das ist kein Problem, sondern eine Chance! Genau solche überraschenden Funde sind oft der Ausgangspunkt für komplett neue Forschungsfragen.
Dokumentiere diese Ergebnisse ganz objektiv und versuche, plausible Erklärungen dafür zu finden. Vielleicht hast du einen neuen Trend aufgedeckt oder eine etablierte Theorie stößt an ihre Grenzen. Das Wichtigste ist, transparent zu bleiben und nicht in die Versuchung zu geraten, die Daten so zu „biegen“, dass sie doch noch irgendwie zur ursprünglichen Annahme passen.
Ein gutes Praxisbeispiel für die Erfassung solcher Stimmungsbilder liefert die politische Forschung. Der ARD-DeutschlandTREND vom Januar 2025 von Infratest dimap zeigte zum Beispiel die drängendsten Probleme aus Sicht der Deutschen. In dieser Umfrage nannten 37 % der Befragten die Zuwanderung als wichtigstes Thema, direkt gefolgt von der Wirtschaft mit 33 %. Solche Analysen machen gesellschaftliche Prioritäten sichtbar und beeinflussen, wie politische Strategien entwickelt werden.
Bist du bereit, die Auswertung deiner nächsten Hausarbeit auf ein neues Level zu heben? Mit IntelliSchreiber kannst du in wenigen Minuten eine vollständig strukturierte Arbeit mit echten, überprüfbaren Quellen erstellen lassen. Gib einfach dein Thema an und unser KI-Tool erledigt den Rest – inklusive perfekter Zitate und Literaturverzeichnis. Spare Zeit, vermeide Stress und sichere dir bessere Noten. Probiere IntelliSchreiber jetzt aus und überzeuge dich selbst!